
Comprenez les Diffusion Transformers (DiTs), l’architecture qui combine modèles de diffusion et attention pour générer des images depuis du bruit.
Diffusion Transformers (DiTs) : comprendre l’architecture qui combine diffusion et attention
Du bruit à l’image : la magie contrôlée des Diffusion Transformers
Comment les DiTs combinent diffusion et attention pour générer des contenus visuels
Imaginez une toile remplie de parasites gris, comme l’écran d’une vieille télévision sans signal. Vous écrivez : « un renard roux dans une forêt enneigée, lumière cinématographique ». Quelques secondes plus tard, les taches se réorganisent : des contours apparaissent, puis une fourrure, des arbres, une ambiance. C’est l’intuition de base derrière des outils comme Stable Diffusion et Midjourney : générer une image à partir d’un prompt textuel.
Le cœur du mécanisme est le débruitage progressif. Pendant l’entraînement, le modèle apprend à reconnaître comment une image propre peut être peu à peu dégradée par du bruit. Lors de la génération, il fait l’inverse : il retire progressivement le bruit pour produire une image de haute qualité. L'instruction de l’utilisateur sert de guide : ces modèles sont entraînés sur de grands ensembles d’images associées à des descriptions textuelles, puis utilisent le prompt pour orienter chaque étape du nettoyage.
Les Diffusion Transformers, ou DiTs, partent de cette idée simple et y ajoutent une seconde brique célèbre de l’IA moderne : l’attention des Transformers. Autrement dit, des architectures récentes peuvent combiner une attention de type transformeur avec un raffinement itératif de type diffusion. La diffusion apporte le principe du raffinement depuis le bruit ; le Transformer aide le modèle à relier les éléments importants entre eux. La promesse des DiTs tient dans cette rencontre : mieux structurer ce qui apparaît, étape après étape.
Pourquoi les Diffusion Transformers comptent

Familles de modèles génératifs
Les Diffusion Transformers comptent d’abord parce qu’ils réunissent deux lignées majeures de l’IA générative. Le paysage ne se limite pas à une seule approche : il comprend VAE, les GAN, les modèles de diffusion, les transformeurs et les NeRF. Les DiTs s’inscrivent donc dans une famille plus large, mais avec une position particulière : ils empruntent la logique de génération par diffusion et la capacité des Transformers à modéliser des dépendances complexes.
Motifs des données
Le point commun de ces modèles est simple : ils apprennent des motifs dans les données d’entraînement pour produire ensuite de nouveaux exemples. L’intérêt des DiTs est de mieux exploiter ces motifs lorsque les données sont riches, structurées et composées de nombreux éléments liés entre eux.
Images, vidéo, audio, 3D
Historiquement, la diffusion s’est surtout imposée dans les médias continus : images, vidéos et fichiers audio. Cette proximité avec les signaux visuels et sonores explique pourquoi les DiTs intéressent autant les systèmes capables de générer des images haute résolution, des séquences vidéo, de l’audio, ou de dialoguer avec des représentations 3D dans un pipeline plus large.
Essor du texte
En parallèle, le texte est devenu le terrain dominant des Transformers : ils constituent le principal type de modèle génératif derrière des produits comme ChatGPT et Gemini. Des travaux récents explorent aussi l’usage des modèles de diffusion pour l’analyse et la génération de texte, ce qui rapproche encore les deux mondes.
Importance multimodale

La portée durable des DiTs vient de là : ils offrent un langage architectural commun pour relier texte, image, vidéo, son et autres représentations. Ils ne remplacent pas tous les modèles génératifs, mais ils deviennent un candidat naturel quand un système doit combiner plusieurs modalités plutôt que générer un seul type de contenu isolé.
La diffusion, expliquée simplement
L’analogie de la photo floue
Imaginez une photo nette que l’on dégrade peu à peu. À chaque étape, on ajoute une petite dose de bruit, jusqu’à ce que les contours, les couleurs et les détails disparaissent presque complètement. C’est l’intuition du processus direct : pendant l’entraînement, le modèle voit des données auxquelles on ajoute progressivement du bruit, afin d’apprendre comment elles se dégradent sous l’effet du bruit.
Ce bruit est généralement modélisé comme du bruit gaussien, une forme de bruit aléatoire bien connue en statistiques. Dans une diffusion complète, les données réelles sont progressivement corrompues en bruit pur sur T étapes : quand on arrive vers la dernière étape, il ne reste presque plus qu’un nuage aléatoire.
La génération utilise alors le processus inverse. Un modèle de diffusion est justement un modèle génératif qui apprend à inverser ce processus graduel d’ajout de bruit pour produire des images, de l’audio, de la vidéo ou même de la 3D. Il part d’un bruit pur, puis tente de retirer un peu de bruit à chaque étape, jusqu’à obtenir une donnée cohérente.
L’analogie de la photo floue a toutefois une limite : le modèle ne “retrouve” pas une photo cachée dans le bruit. Il génère un nouvel échantillon plausible, similaire aux données apprises, mais pas identique à une donnée d’origine.
Le nombre d’étapes
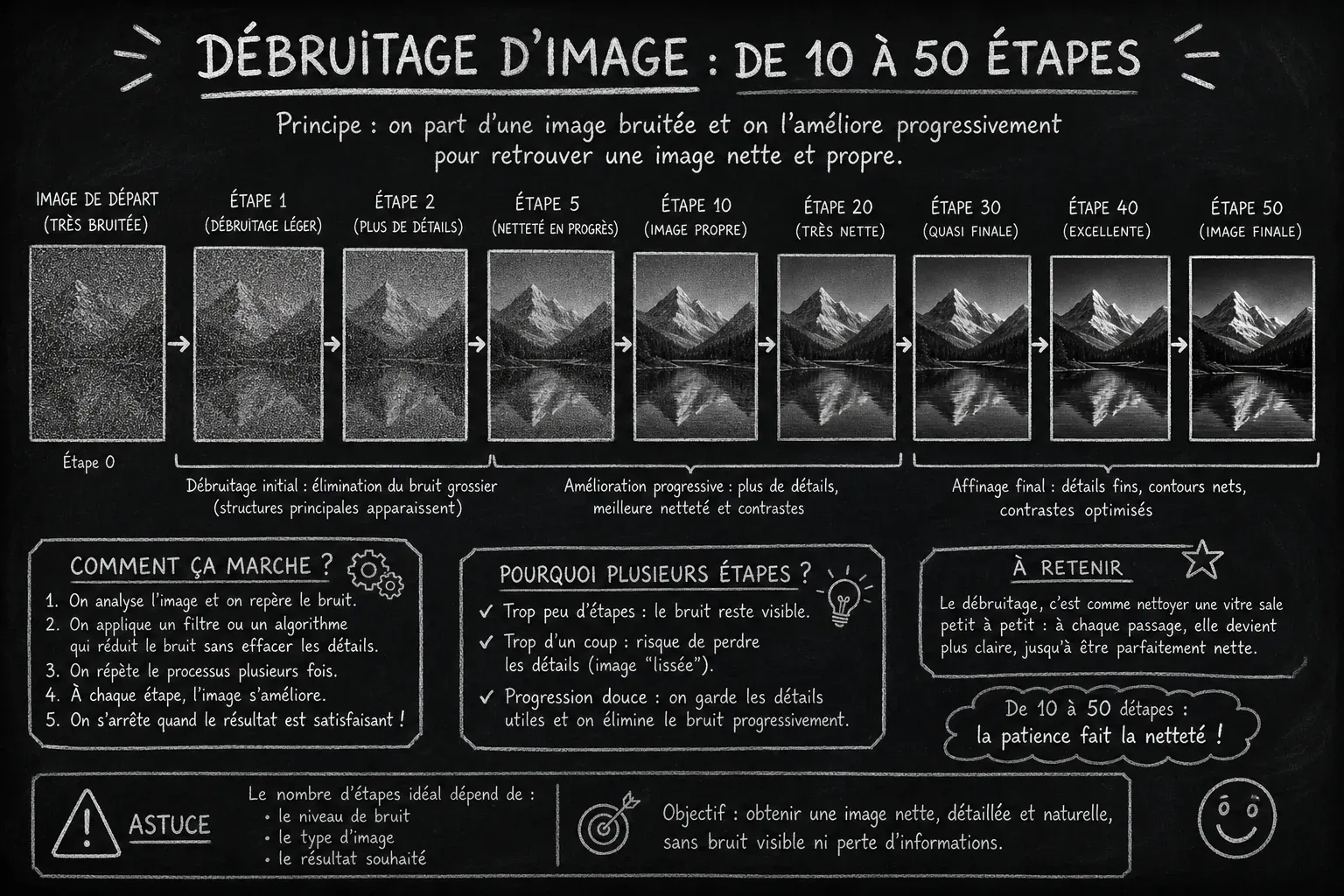
Le débruitage ne se fait pas en un seul geste. En pratique, les modèles de diffusion utilisent souvent des dizaines d’itérations, par exemple 10 à 50 étapes avec des échantillonneurs modernes, parfois davantage selon la qualité visée et le type de contenu. Chaque étape corrige une partie de l’erreur, comme si l’image devenait progressivement plus lisible.
Ce nombre d’itérations est un réglage important : plus d’étapes peuvent améliorer la qualité, mais ralentissent la génération. À l’inverse, moins d’étapes accélèrent le résultat, avec un risque de détails moins propres ou moins stables. C’est le compromis classique vitesse qualité.
Des techniques récentes cherchent à réduire ce coût. Les méthodes de distillation et les approches de type consistency peuvent ramener ce nombre à une poignée d’étapes, voire à une seule. Elles rendent la diffusion plus pratique, sans supprimer complètement l’arbitrage entre rapidité, fidélité et contrôle.
Le Transformer, expliqué simplement
Pourquoi des tokens plutôt que des mots entiers
Un Transformer ne lit pas directement une phrase comme une suite de mots “naturels”. Il commence par découper l’entrée en tokens : petits morceaux manipulables par le modèle. Dans le texte, un token peut être un mot court, une partie de mot, un signe de ponctuation ou un symbole. Ce choix évite d’avoir un vocabulaire gigantesque contenant tous les mots possibles, toutes leurs conjugaisons et toutes leurs fautes. Le modèle travaille plutôt avec un vocabulaire contrôlé, réutilisable pour composer des formes nouvelles.
La même idée s’étend au-delà du langage. Pour une image, on peut raisonner en unités d’image : petits patchs, régions ou représentations compressées. Chaque unité devient alors l’équivalent d’un token que le modèle peut comparer aux autres. C’est essentiel pour les modèles multimodaux : texte, image, audio ou vidéo peuvent être ramenés à des suites d’unités calculables. Autrement dit, les transformeurs découpent les données d’entrée en tokens avant d’évaluer leurs relations.
Ces tokens sont ensuite convertis en embeddings, c’est-à-dire en vecteurs numériques. Comme un Transformer ne possède pas naturellement la notion de “premier”, “dernier” ou “à côté”, il faut aussi lui ajouter une information de position. Les Transformers ajoutent des informations positionnelles aux embeddings : historiquement avec des fonctions sinusoïdales, et dans certains modèles modernes avec des positions apprises.
Ce que l’attention mesure
L’attention sert à répondre à une question simple : quels autres tokens sont utiles pour comprendre celui-ci ? Dans une phrase, le sujet peut influencer un verbe placé plus loin. Dans une image, une zone peut être cohérente avec une autre zone distante. C’est pourquoi les Transformers sont souvent appréciés pour interpréter le contexte et identifier des relations de longue portée.
Techniquement, chaque token est projeté en trois vecteurs : requête (Q), clé (K) et valeur (V). La requête représente ce qu’un token “cherche”, la clé ce que les autres tokens “annoncent”, et la valeur l’information à transmettre. Les scores d’attention sont calculés par produit scalaire entre requêtes et clés, puis normalisés pour pondérer les valeurs.
L’attention n’est pas unique : elle est généralement multi-tête. Plusieurs attentions fonctionnent en parallèle, chacune pouvant repérer un type de relation différent : proximité locale, correspondance sémantique, structure globale, répétition de motif. L’attention multi-tête exécute plusieurs mécanismes d’attention en parallèle, ce qui enrichit la représentation finale.
Un bloc Transformer empile cette attention avec d’autres composants : attention multi-tête, réseau feed-forward, connexions résiduelles et normalisation de couche. Comme les tokens d’une séquence peuvent être traités en parallèle, les Transformers traitent les séquences en parallèle plutôt que mot par mot, ce qui les rend adaptés aux grands contextes — et, plus tard, aux unités d’image utilisées dans les modèles de diffusion.
Alors, qu’est-ce qu’un Diffusion Transformer ?
Du U-Net au Transformer
Un Diffusion Transformer, ou DiT, est une architecture qui combine deux mécanismes : un processus de diffusion, qui part d’une donnée bruitée et la raffine progressivement, et des blocs Transformer, qui modélisent les relations entre les éléments de cette donnée. Autrement dit, le DiT ne génère pas une image comme un texte mot après mot : il apprend à transformer un état dégradé en état plus propre, étape après étape.
Historiquement, beaucoup de modèles de diffusion d’images se sont appuyés sur un U-Net : les modèles de diffusion utilisent souvent une architecture de type U-Net, ou un U-Net opérant dans un espace latent. Le U-Net est efficace pour traiter des cartes visuelles à plusieurs résolutions, avec une structure encodeur-décodeur adaptée aux images. Dans un DiT, l’idée centrale est de remplacer ce cœur U-Net par une pile de blocs Transformer.
Ce remplacement devient naturel quand l’image n’est plus vue seulement comme une grille de pixels, mais comme une séquence de tokens visuels : des patchs d’image, ou plus souvent des représentations dans un espace latent plus compact. Le Transformer peut alors appliquer l’attention entre ces tokens. Dans les DiTs visuels, cette attention est généralement complète ou bidirectionnelle : chaque token peut être exprimé en fonction de tous les autres tokens bruités. L’attention masquée, où chaque position ne voit que les tokens précédents, concerne surtout les décodeurs auto-régressifs de type GPT ou certaines variantes, mais ce n’est pas le fonctionnement canonique d’un DiT d’image.
La logique d’un DiT
Concrètement, un DiT découpe ou projette l’état bruité en patchs ou en tokens latents, puis applique plusieurs fois le même type d’opération : attention, transformation non linéaire, normalisation, et retour vers une représentation exploitable par la diffusion. À chaque étape, le modèle reçoit aussi une information de temps de diffusion : elle lui indique à quel niveau de bruit il se trouve et quel type de correction il doit apprendre.
Il faut distinguer cela de l’architecture Transformer complète d’origine, qui est de type encodeur-décodeur : l’encodeur lit une séquence d’entrée, le décodeur produit une sortie, avec une attention entre les deux. Les familles modernes se spécialisent ensuite : BERT utilise la pile d’encodeurs, GPT la pile de décodeurs, et T5 l’encodeur-décodeur complet. Un DiT peut s’inspirer de ces briques, mais son objectif reste celui de la diffusion : raffiner itérativement une représentation bruitée jusqu’à prédire le bruit à retirer, ou une version plus propre du latent.
Comment un DiT s’entraîne et génère une sortie
Pendant l’entraînement

Un DiT commence par un pré-entraînement massif sur de grands jeux de données, souvent composés de paires image-texte lorsque l’objectif est de générer une image à partir d’un prompt. L’idée n’est pas d’apprendre une image par cœur, mais d’exposer le modèle à assez d’exemples pour qu’il repère des régularités statistiques : textures, formes, styles, relations entre mots et contenus visuels.
À chaque étape, la donnée propre est volontairement corrompue. Pour une image, on ajoute du bruit ; pour une sortie textuelle de type diffusion, on peut masquer une partie des tokens. Le modèle reçoit donc une version dégradée, plus une condition éventuelle comme le prompt, puis apprend à prédire ce qui manque ou le bruit à retirer. Dans les variantes textuelles, seule la partie réponse peut être masquée tandis que le prompt reste visible, ce qui illustre bien la séparation entre instruction et contenu à produire.
Les poids du modèle sont ajustés pour réduire l’écart entre sa prédiction et la cible attendue. Peu à peu, les blocs Transformer apprennent quelles parties de l’entrée doivent s’influencer mutuellement. Le conditionnement du prompt sert alors de boussole : il indique quelles régularités doivent être activées pour transformer une donnée bruitée en résultat plausible.
Encadré pédagogique — non prescriptif. Ce dossier ne fournit ni hyperparamètres typiques, ni pseudo-code complet. Les étapes ci-dessus décrivent le principe général ; dans un système réel, le calendrier de bruit, la taille du modèle, le nombre d’itérations et les pertes d’entraînement dépendent fortement du cas d’usage.
Pendant l’inférence
À la génération, le processus repart d’un bruit initial — ou, dans certaines approches textuelles, d’un prompt suivi de positions masquées. Les modèles de diffusion textuels récents sont ainsi décrits comme partant du prompt, d’un token de début, puis de masques sur le reste de la réponse.
Le DiT applique ensuite des itérations successives. À chaque passage, il estime comment rendre l’état courant un peu moins bruité et un peu plus compatible avec la condition. C’est ce raffinement progressif qui distingue ce fonctionnement d’une génération strictement mot par mot : un Transformer de diffusion part d’un contenu bruité pour l’affiner itérativement en réponse cohérente.
Le classifier-free guidance renforce ce guidage : le modèle est entraîné avec des entrées conditionnées et non conditionnées, puis les prédictions sont mélangées en inférence afin de rapprocher l’échantillon du prompt. Un guidage plus fort peut rendre la sortie plus fidèle, mais aussi moins naturelle s’il est mal dosé.
Enfin, le nombre d’étapes règle le compromis entre vitesse et qualité : pour les LLM de diffusion, il est présenté comme un paramètre situé dans les dizaines ou les faibles centaines d’étapes. Le résultat final est donc une sortie affinée, cohérente avec la condition, obtenue par corrections successives plutôt que par une seule décision instantanée.
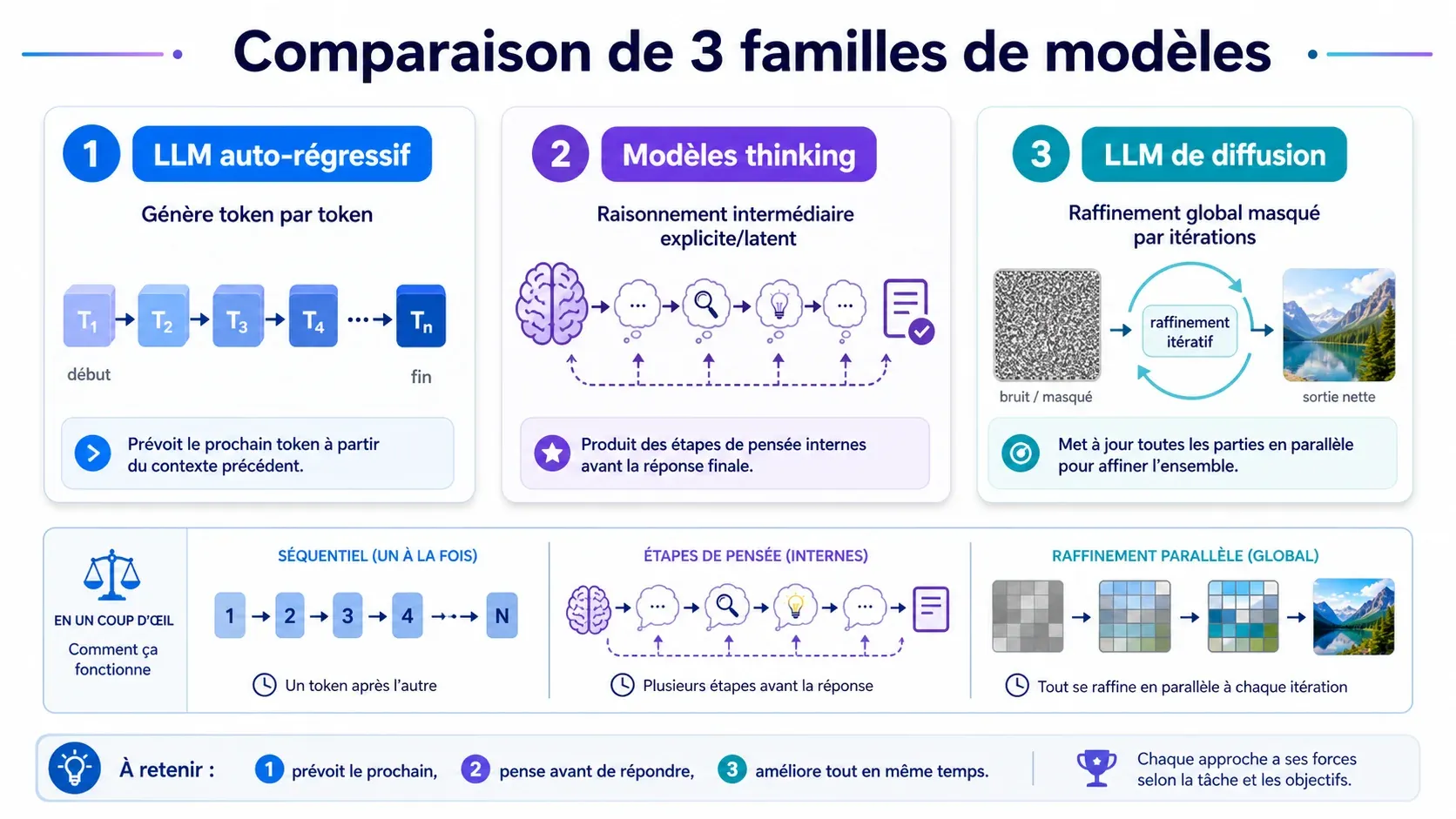
DiTs, LLM et “thinking” : ce qui change vraiment
Le cas classique des LLM
Un LLM comme ceux derrière ChatGPT ou Gemini travaille sur du texte tokenisé : mots, morceaux de mots et signes sont convertis en tokens. Ces produits reposent largement sur des transformeurs, devenus le type de modèle central de nombreux grands services de GenAI. Pendant le pré-entraînement, le modèle parcourt d’immenses corpus et ajuste ses paramètres pour apprendre des régularités de langue, de connaissances et de raisonnement apparent. Cette échelle compte : les transformeurs requièrent de grands jeux de données pour être entraînés efficacement.
À l’inférence, le principe reste auto-régressif : le modèle prédit le token suivant, puis recommence en s’appuyant sur les tokens déjà produits. La génération ressemble donc à une écriture mot à mot. Surtout, dans les modèles de texte auto-régressifs comme GPT, la génération se fait un token à la fois sans révision des tokens déjà générés : un token sorti est généralement figé.
Les modèles instruct améliorent l’obéissance aux consignes, le dialogue et le respect d’un format, mais pas ce mécanisme. Les modèles dits thinking peuvent produire plus d’étapes intermédiaires ou de raisonnement visible, sans pour autant réécrire globalement toute la réponse comme le ferait une diffusion.
Le cas des LLM de diffusion
Les LLM de diffusion explorent une autre logique : partir d’une séquence avec des tokens masqués, puis la raffiner en plusieurs passes. L’idée rappelle BERT, entraîné à reconstruire des tokens manquants à partir du contexte, plutôt qu’à seulement prédire le prochain token de gauche à droite.
Dans une diffusion masquée, la réponse ressemble davantage à un brouillon complété et corrigé progressivement : certains tokens sont proposés, d’autres restent masqués, puis l’ensemble peut être révisé. C’est la différence utile avec les LLM classiques : moins d’ajout irréversible, plus de raffinement global.
La fenêtre de contexte reste importante, car elle limite ce que le modèle considère simultanément. Or les fenêtres de contexte ont fortement augmenté, de 512 tokens dans le Transformer original à des centaines de milliers, voire millions, dans certains LLM récents. Mais une grande fenêtre ne suffit pas : ce qui change vraiment, c’est le mode de génération.
Ce que les DiTs permettent dans les systèmes multimodaux
Contrôler la génération
Dans un système multimodal, un DiT ne reçoit pas seulement du bruit à transformer en image : il peut aussi être conditionné par du texte, une image de départ ou des contraintes spatiales. C’est ce qui permet les usages classiques de texte vers image, mais aussi l’image vers image, où l’on conserve une composition tout en changeant le style, l’ambiance ou certains détails. Les modèles de diffusion se sont ainsi étendus à des usages de modification d’image et d’upscaling, donnant davantage de contrôle à l’utilisateur.
Ce contrôle devient plus précis avec des entrées structurées : un masque d’image indique quelles zones doivent être modifiées ou préservées ; une carte de profondeur aide à maintenir la géométrie de la scène ; des informations de pose ou de segmentation guident la position d’un corps, d’un objet ou d’un arrière-plan. L’inpainting s’appuie sur cette logique : on remplace localement une partie manquante ou indésirable sans régénérer toute l’image. De même, l’upscaling peut enrichir une image existante en haute résolution tout en respectant son contenu global.
Adapter un modèle
L’autre levier important est l’adaptation. Plutôt que de réentraîner un grand modèle complet, on peut ajouter un LoRA : un petit modèle qui modifie un modèle plus large, souvent pour apprendre un style graphique, un personnage récurrent, un type de produit ou une contrainte visuelle spécifique.
L’intérêt pratique est évident : un LoRA pèse généralement entre 50 et 500 Mo, là où un modèle complet peut atteindre plusieurs gigaoctets. On peut aussi combiner des LoRAs pour mélanger des effets, par exemple un style et un personnage. Cette logique apparaît dans des outils récents : Flux.2 est présenté comme utilisant des LoRAs pour affiner la génération haute résolution, Z-Image Turbo comme pouvant en combiner jusqu’à trois, et Qwen-Image-Edit comme intégrant certains LoRAs directement. Mais cette modularité reste limitée : au-delà de quelques LoRAs simultanés, souvent trois ou quatre, les interactions deviennent imprévisibles, ce qui impose des tests et des compromis.
Avantages et compromis face aux GAN et aux U-Net
Stabilité d’entraînement
Face aux GAN, les DiT héritent d’un avantage général des modèles de diffusion : l’objectif d’apprentissage est souvent plus stable que l’affrontement générateur-discriminateur. Les GAN restent puissants, mais ils sont réputés plus difficiles à entraîner et sujets à l’effondrement de modes. D’autres synthèses présentent aussi la diffusion comme moins exposée à certains risques d’entraînement.
Contrôle utilisateur
Le compromis ne se résume donc pas à “meilleure qualité contre vitesse”. Les modèles de diffusion, dont les DiT, privilégient souvent l’apprentissage stable et le contrôle : texte, image de référence, masque, profondeur ou autres conditions peuvent guider le débruitage. Par rapport aux U-Net, les DiT changent surtout la manière de modéliser les relations globales via l’attention ; cela ne rend pas automatiquement tout meilleur, mais ouvre des choix d’architecture plus scalables.
Latence d’inférence
Le revers est la latence. Un DiT génère par étapes successives : même accélérée, la diffusion reste généralement plus lente que les GAN, car elle repose sur des étapes itératives de débruitage. Les échantillonneurs modernes peuvent descendre à 10–50 étapes, et certaines distillations à quelques étapes, mais cela ne supprime pas toujours le coût.
GAN temps réel
Pour des usages interactifs stricts — filtres vidéo, avatars, rendu embarqué — les GAN gardent un avantage : ils peuvent produire des échantillons réalistes en un ou quelques passages avant et restent adaptés à la génération en temps réel.
Évaluation probabiliste
Les modèles de diffusion sont aussi plus faciles à rattacher à une lecture probabiliste : ils peuvent être reliés à des formulations de vraisemblance, alors que les GAN, non fondés sur la vraisemblance, se jugent souvent via des métriques perceptuelles ou statistiques.
Coût de calcul
Enfin, les DiT déplacent le coût : attention, grands lots, longues résolutions et multiples pas d’inférence pèsent lourd. Le dossier ne contient pas de benchmarks chiffrés DiT versus U-Net ; la comparaison doit donc rester qualitative, ou être complétée par des sources de mesure dédiées.
Limites, risques et bonnes pratiques
Limites techniques
Un DiT cumule deux sources de coût : le processus de diffusion, qui génère par étapes successives, et les blocs Transformer, souvent lourds à entraîner. En pratique, les modèles de diffusion peuvent nécessiter une puissance de calcul importante, tandis que les transformers exigent aussi une puissance de calcul élevée. Résultat : l’entraînement peut être long, coûteux, et réservé à des équipes disposant de GPU nombreux, de données bien préparées et d’une ingénierie solide.
L’inférence est elle aussi un point sensible. Même avec des accélérations, générer une image, une vidéo ou un signal complexe demande souvent plusieurs passes de débruitage, ce qui rend les DiTs moins instantanés que des modèles qui produisent directement une sortie. À cela s’ajoute la mémoire : les transformers consomment beaucoup de mémoire, en particulier sur les longues séquences. Les très grandes images, les vidéos longues ou les entrées multimodales étendues peuvent donc dépasser rapidement les capacités disponibles.
La longueur d’entrée reste une autre contrainte : la scalabilité des Transformers est contrainte par des besoins élevés en calcul et en mémoire, avec des limites pratiques sur ce que le modèle peut traiter en une fois. Enfin, les DiTs apprennent d’autant mieux que les données sont nombreuses et variées : les transformers nécessitent de grands jeux de données. Sur des données rares, spécialisées ou coûteuses à collecter, le risque de surapprentissage augmente, surtout si le modèle n’est pas correctement régularisé.
Limites de fiabilité
Un DiT ne “comprend” pas son résultat comme un humain. Il optimise une génération plausible au regard de ses données et de son conditionnement. Il peut donc produire des détails inventés, incohérents ou trop confiants : une image médicalement trompeuse, une scène physiquement impossible, ou un objet qui semble correct mais ne l’est pas. Cette difficulté est renforcée par le fait que les transformers peuvent se comporter comme des boîtes noires, ce qui complique l’explication précise d’une erreur.

Les biais sont également centraux, notamment le biais culturel. Si les données d’entraînement sous-représentent certaines populations, styles, langues ou contextes, le modèle peut reproduire ces déséquilibres. Il ne connaît pas non plus automatiquement le présent : sauf mise à jour, fine-tuning ou connexion à des sources externes fiables, il reflète surtout son corpus d’entraînement.
Enfin, la qualité visuelle des modèles de diffusion crée un risque éditorial majeur : les avancées des modèles de diffusion ont amélioré la qualité et le réalisme des images générées, jusqu’aux deepfakes convaincants. Bonnes pratiques : documenter les données, tester les biais, limiter les usages sensibles, signaler les contenus synthétiques, garder une validation humaine et prévoir des garde-fous contre l’usurpation, la désinformation et les usages non consentis.
Récapitulatif : retenir les Diffusion Transformers en cinq idées

Diffusion par débruitage
Un Diffusion Transformer part d’une idée simple : apprendre à retirer du bruit. À la génération, il remonte progressivement d’un état très bruité vers une donnée cohérente, comme une image, une vidéo ou un son.
Attention par tokens
Au lieu de traiter seulement des pixels voisins comme un U-Net classique, il découpe la donnée en tokens et utilise l’attention pour relier des zones éloignées. Cela l’aide à mieux gérer la structure globale.
Raffinement itératif
Contrairement à un LLM auto-régressif, qui produit souvent un token après l’autre, un DiT améliore toute la sortie par étapes. La génération ressemble davantage à une correction répétée qu’à une phrase écrite de gauche à droite.
Multimodalité contrôlable
Les DiTs deviennent puissants quand on les conditionne : texte, image de référence, masque, audio ou contraintes de style peuvent guider le résultat.
Compromis vitesse qualité
Leur force a un coût : plusieurs passes de débruitage demandent du calcul. Réduire les étapes accélère l’inférence, mais peut dégrader la précision ou les détails.
Limites de fiabilité
Un DiT ne “comprend” pas toujours ce qu’il produit. Il peut inventer, mal suivre une consigne, reproduire des biais ou échouer sur des contraintes fines. Sa qualité dépend donc autant du modèle que des données, du guidage et des contrôles autour de lui.
